Dyk dybere: OneLake og Direct Lake i Microsoft Fabric
I min introduktion til Microsoft Fabric kom jeg ind på et par af de grundlæggende byggeklodser, der gør det muligt at forene data og analyser i ét samlet miljø. Men for at virkelig forstå styrken ved platformen, er det værd at kigge nærmere på to centrale koncepter: OneLake og Direct Lake. Disse teknologier udgør rygraden i, hvordan Fabric revolutionerer dataopbevaring og -tilgængelighed. Lad os dykke dybere ned.
Dataintegration uden begrænsninger
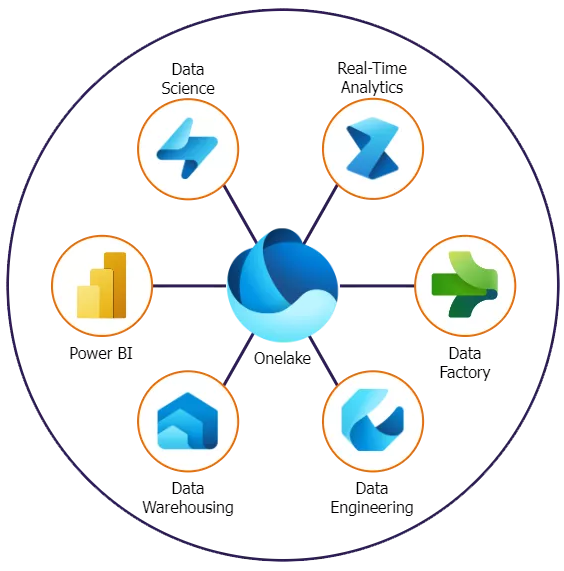
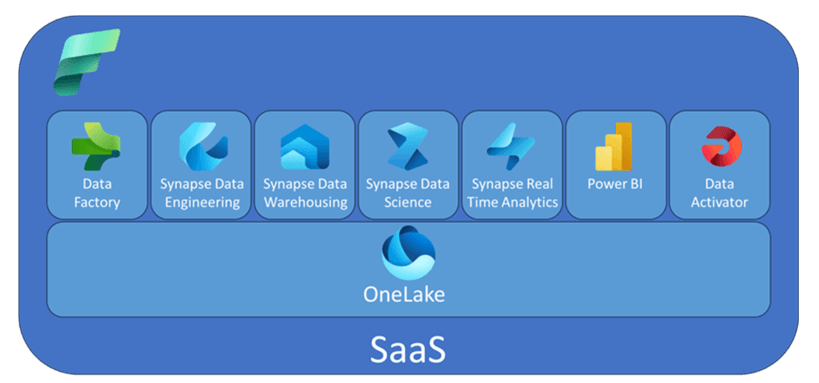
Tænk på OneLake som en "lakehouse"-løsning, hvor alle dine data er samlet i én fælles struktur. Den fungerer som det universelle datalager for hele Microsoft Fabric-økosystemet. Fordelene ved OneLake gør det til en gamechanger for datadrevne organisationer.
1. Centraliseret dataopbevaring: OneLake samler alle data ét sted, uanset om det kommer fra forskellige kilder som Azure Data Lake, SQL-baserede systemer eller tredjepartstjenester.
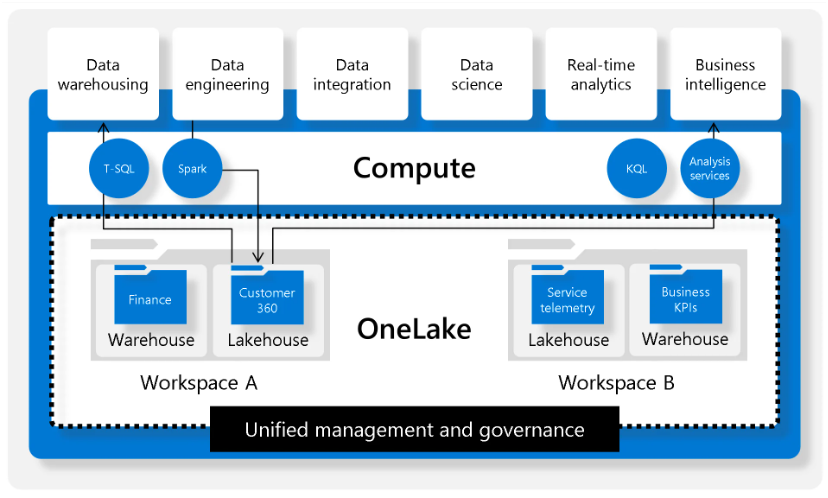
2. Understøtter både struktureret og ustruktureret data: Struktureret data lagres i det åbne Delta Parquet-format, hvilket muliggør nem integration med andre systemer og værktøjer uden behov for komplicerede konverteringer. Ustruktureret data kan ligge i samme filsystem, så det nemt kan tilgås og behandles af Spark.
3. Indbygget versionering og governance: OneLake håndterer datastyring, adgangsrettigheder og versionering som en del af platformens kerne.
4. Data sharing uden kopiering: I stedet for at oprette kopier kan OneLake dele data direkte med andre services via standarder som Delta Sharing.
Praktisk eksempel:
Forestil dig, at du har data fra en CRM-platform, en ERP-løsning og en marketingplatform. Med OneLake kan alle disse datakilder kombineres uden at skulle flyttes fysisk. Det sparer lageromkostninger og forbedrer ydeevnen.