At cVation, we mostly ensure our quality with automated tests, which both help us secure the business logic straight away, but also protect us against regressions in the future. When we develop new features, they are accompanied by a series of tests, that ensure that the new code works as it should in different situations. When the tests pass, we can relax, pat ourselves on the shoulders and be sure that the code has a high quality. Right? Or not?
How can you trust your tests with peace of mind? The testing we do is also code, and that code could - like the code we try to ensure the quality of - contain errors. How do we know that the automated tests are testing what we expect? Is it possible for our tests at all to detect defects we have not been able to predict ourselves? How do we ensure the quality of our quality assurance?
Code coverage
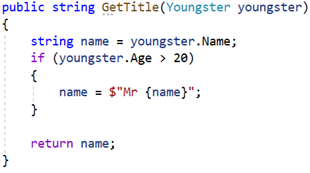
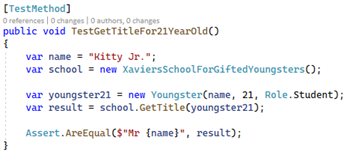
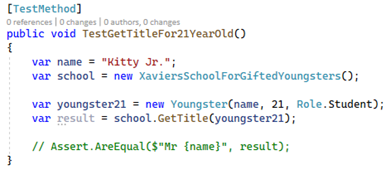
We could write new tests of our tests, but to avoid this endless recursion we must come up with something better. Many use code coverage for this. This concept is about measuring how much of the code is affected through the existing tests. Let us take a concrete example. This simple method accepts a person and returns the person's title. The method is intended to return the person's name with “Mr. " in front, if the person is 21 years or older: