Hos cVation har vi et stærkt DevOps-fokus, hvor vi stræber efter at håndtere opgaverne udfra en kundecentreret tilgang. Vores primære mål er at forene både udviklernes og operations' interesser, selv når de konflikter (f.eks. i ønsket om lancering af nye features uden restriktioner versus modviljen mod at ændre noget i et ellers velfungerende system).
Site Reliability Engineering (SRE)
SRE blev udviklet og lanceret af Google til at håndtere deres systemer i large scale. Dog er principperne og praksisserne inden for SRE som en ingeniørdisciplin blevet vedtaget af mange andre organisationer for at forbedre pålideligheden af deres software-systemer. SRE er i bund og grund en række praksisser og principper, der kombinerer software engineering og drift for at sikre pålidelighed, ydeevne og tilgængelighed af komplekse software-systemer gennem brug af automatisering, overvågning, håndtering af hændelser og kontinuerlig forbedring.
Site Reliability Engineering (SRE) sigter mod at hjælpe organisationer med at opnå bæredygtige niveauer af pålidelighed i deres systemer. En vigtig aspekt er også at finde den rette balance mellem agilitet og stabilitet for den enkelte virksomhed.
Ansvarsområderne for SRE-teams inkluderer:
Tilgængelighed / pålidelighed / latenstid / performance / effektivitet / change management / overvågning / emergency response og kapacitetsplanlægning af tjenester.
For at give et team mulighed for at gøre dette i stor skala, sigter vi mod at automatisere eller eliminere alle repeterende opgaver. SRE-teamet lægger vægt på, at systemdesignet fungerer pålideligt, selv når der sker hyppige opdateringer fra udviklingsteams.
For at SRE-teamet kan tilpasses til et system under udvikling, skal det være designet med observabilitet for øje, dvs. det skal have en høj grad af overvågning. Med andre ord skal der logges tilstrækkeligt med data i systemet for at der kan foretages ordentlige undersøgelser. Det giver SRE-teamet mulighed for konstant at vurdere nye brugerflows og overvåge kritiske processer for projektet.
Agilitet versus Stabilitet
Historisk set har kløften mellem udvikling og drift ofte kunne resultere i en konflikt om, hvad der er vigtigst: Agilitet for at kunne lancere nye funktioner eller opretholdelse af stabiliten i systemet for kunden.
SRE-konceptet giver os mulighed for at drøfte dette dilemma ved at anvende Service Level Indicators (SLI), Service Level Objectives (SLO) og et resulterende fejlbudget.
SLI kan oversættes til overvågning af vigtige brugerflows, f.eks. i en IoT-opstilling. Her kan det være, når brugeren installerer en sensor og bekræfter, at den er aktiv i et administrationspanel. SLO ville hermed betyde reglerne for latenstid, tilgængelighed og den fejlmargen, som brugeren kan forvente.
SLO giver SRE-teamet og virksomheden mulighed for at kommunikere og blive enige om de konkrete tal for oppetid og ydeevne. Forskellen mellem den opmålte SLI og den definerede SLO er det der kaldes fejlbudgettet. Når der performes bedre end aftalt, er det tilladt for udviklingsteamene at lancere nye funktioner så ofte, som de ønsker. Men så snart budgettet er negativt, har SRE-teamet ansvaret for at stoppe lanceringer, at undersøge problemene og fjerne forhindringer -eller give et udvalgt udviklingsteam opgaven med at fjerne dem. I bund og grund betyder en negativt SLO, at projektet dermed skal fokusere på kvalitet. På den måde kan interesse-konflikten mellem drift og udvikling reduceres til at være over eller under den aftalte SLO.
For eksplicit at definere fejlbudgettet, kan vi fortolke det som, hvor meget "upålidelighed" der er tilladt i den aftalte tidsramme. Dette er et vigtigt begreb, da alle implementeringer uanset hvilke medfører risici for upålidelighed, selv de største virksomheder som fx. Microsoft kan indimellem publicere noget, der på trods af alle tests og alle 'best practises' kan resultere i nedetid.
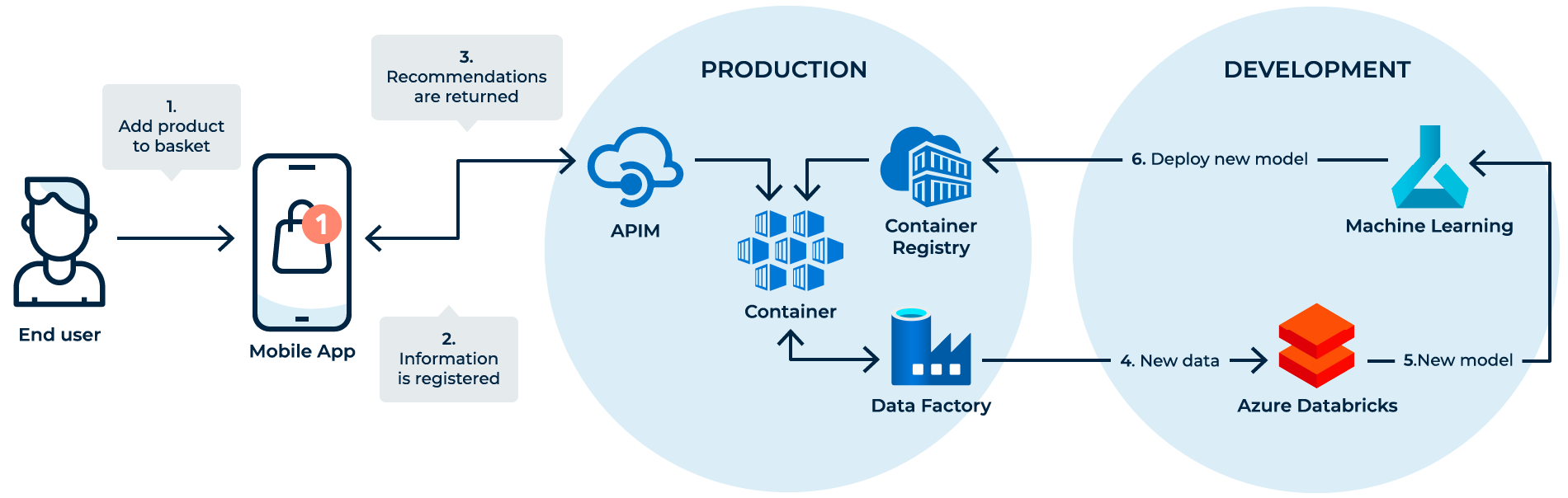
SRE-teamet bliver måske klandret for kun at fokusere på brugerflows vs. tilgængelighed eller svartid, men et brugerflow kan også ses fra et forretningsmæssigt perspektiv, som fx. indtægt eller churn (kundeafgang). Lad os se på det ud fra følgende eksempel, hvor vi har en Machine Learning set-up, der genererer anbefalinger til brugerne.